Immutable data performance
"Immutable" is a recent discussion point around the water cooler, and it's not my imagination when I say "recent":

I think this comes from the functional programming rage -- especially in Haskell -- where, since all of your data is immutable, every function is composable and concatenatable since there are no side effects. Neat. It reminds me how people did this years and years ago to make image manipulation much faster with tools like Shake.
But since that's gotten so much hype over the last couple years, people are now thinking immutable data is a good idea in all languages in all situations. It's not. Immutability can hurt performance significantly.
Take this really really simple example in Python:
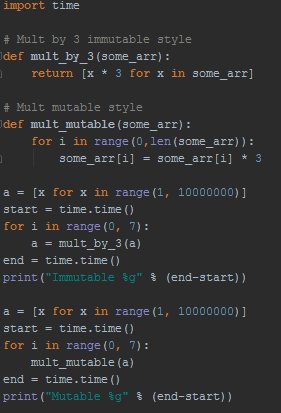
I tried this with PyPy as well. It made no difference. The "immutable" version takes about 2x as long as the mutable version" (9.682s vs. 5.312s on my machine in the most recent test)
Same thing in Java.
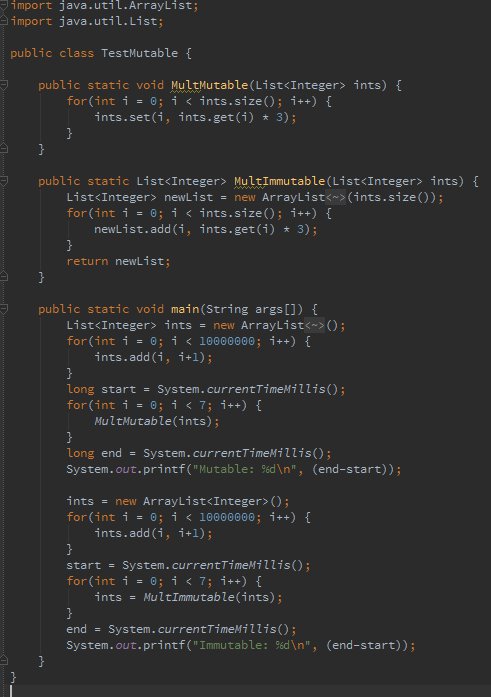
This comes out to be 7.317 vs. 12.736
Long story short, I don't know much about Haskell, but without an optimizer that can concatenate similar functions, immutable data is going to mean allocation. And allocation can kill your performance. I recently heard a work story of someone having a performance problem due to overuse of list comprehensions in Python. I don't know enough to chalk that story off to this trend, but it fits.
FWIW, there's a reason that languages with mutable data like C++ and C# use "out" and "ref". You can have good performance and good self-documentation as to what your function is going to do with that data. Without having to move to a language that only works on data in immutable fashion.